Thomas Wolf
About
Co-founder at @HuggingFace - moonshots - angel
Platforms
Content History
a bit of good grounding in a world of hypeSurge AI: Everyone's acting like models are ready to replace humans in work settings. We put that to the test by creating an entire company and having 9 models act as a customer service agent handling 150 tickets and requests of increasing complexity. Verdict: without common sense, Link: https://x.com/HelloSurgeAI/status/1988337783677604351
We’re releasing a new, extremely high-quality large dataset: *FinePDF-edu* This continues our work on open-sourcing everything possible about the science of pre-training datasets. In this new data, we applied the same filtering techniques we used for the widely adopted *FineWeb-edu*, but this time to our recently published PDF dataset called FinePDF — 3 trillion tokens of Common Crawl PDFs released a few months ago. The result is *FinePDF-edu* a high-quality dataset of about 350B tokens (130B English), representing the most educational slice of all Common Crawl PDFs and outperforming our previously released pretraining dataset on our benchmark. Some details 👇 High-level: - 350B+ highly educational tokens in 69 languages with strong performance - 69 education classifiers powered by ModernBERT and mmBERT - 300k+ EDU annotations per language, generated with Qwen3-235B Method: We filtered this dataset by asking an LLM to score the quality of a large sample (~1M document) among the PDF documents. We then trained a high-quality classifier ModernBERT-Large (and mmBERT for non-English languages) on those LLM-generated scores. We evaluated 10 state-of-the-art open-source LLMs to select our judge and selected Qwen3-235B. We tested different prompts to rate the educational quality of the pdf documents across domains (see details: https://x.com/HKydlicek/status/1988328336469459449?s=20). The final dataset keeps the top 10% of samples based on educational quality, offering excellent pretraining performance while preserving sample token diversity. On our benchmarks FinePDF-edu is best-in-class and can also be mixed with web data for additional variety. Amazing work by the 🍷FineData team. Dataset: https://huggingface.co/datasets/HuggingFaceFW/finepdfs-edu Codebase: https://github.com/huggingface/finepdfs Full collection: https://huggingface.co/collections/HuggingFaceFW/finepdfs

Open-source/science is the most effective way to reduce civilization boot time
we need more team like @pleiasfr pushing open work on synthetic data at scale for pre/mid/post-trainingAlexander Doria: Breaking: we release a fully synthetic generalist dataset for pretraining, SYNTH and two new SOTA reasoning models exclusively trained on it. Despite having seen only 200 billion tokens, Baguettotron is currently best-in-class in its size range. Link: https://x.com/Dorialexander/status/1987930819021635964

omg the http://build.ai team just open-sourced 18 TB (!) of egocentric data like treasure trove for robotics models and physical AIEddy Xu: today, we’re open sourcing the largest egocentric dataset in history. - 10,000 hours - 2,153 factory workers - 1,080,000,000 frames the era of data scaling in robotics is here. (thread) Link: https://x.com/eddybuild/status/1987951619804414416
2024-25 => first time since DeepMind that the UK startups landscape is hot, burning and exciting again imo but the new proposed « exit tax » might just throw a big bucket of cold water on this phoenix follow/sign the @StartupCltn Open Letter if you care about startup ecosystemsHarry Stebbings: I have invested $200M into the UK in the last five years. If @RachelReevesMP implements “Exit Tax” all that funding will go overnight. That is countless jobs, companies and people who will lose out. Rachel, you have managed to steal our hopes, our dreams even our growth, Link: https://x.com/HarryStebbings/status/1987829015248277861
RT Matt Rouif Having fun building the @huggingface @ReachyMiniSol robot 🤖 . It’s very accessible! ♥️@ClementDelangue @julien_c @Thom_Wolf

human-robots interaction is super under-explored/underrated field today Reachy-Mini will be the platform + catalyst to change thatAndi Marafioti: Mixing vision and robotics is incredibly hard, but when it finally works it feels like magic. Link: https://x.com/andimarafioti/status/1986192399534641442
this has been requested so many times by the robotics/LeRobot community, super happy to see EnvHub finally out and in productionjade: We're introducing EnvHub to LeRobot! Upload simulation environments to the @hugginigface hub, and load them in lerobot, with one line of code ! env = lerobot.make_env("username/my-env", trust_remote_code=True) Back in 2017, @OpenAI called on the community to build Gym Link: https://x.com/jadechoghari/status/1986482455235469710

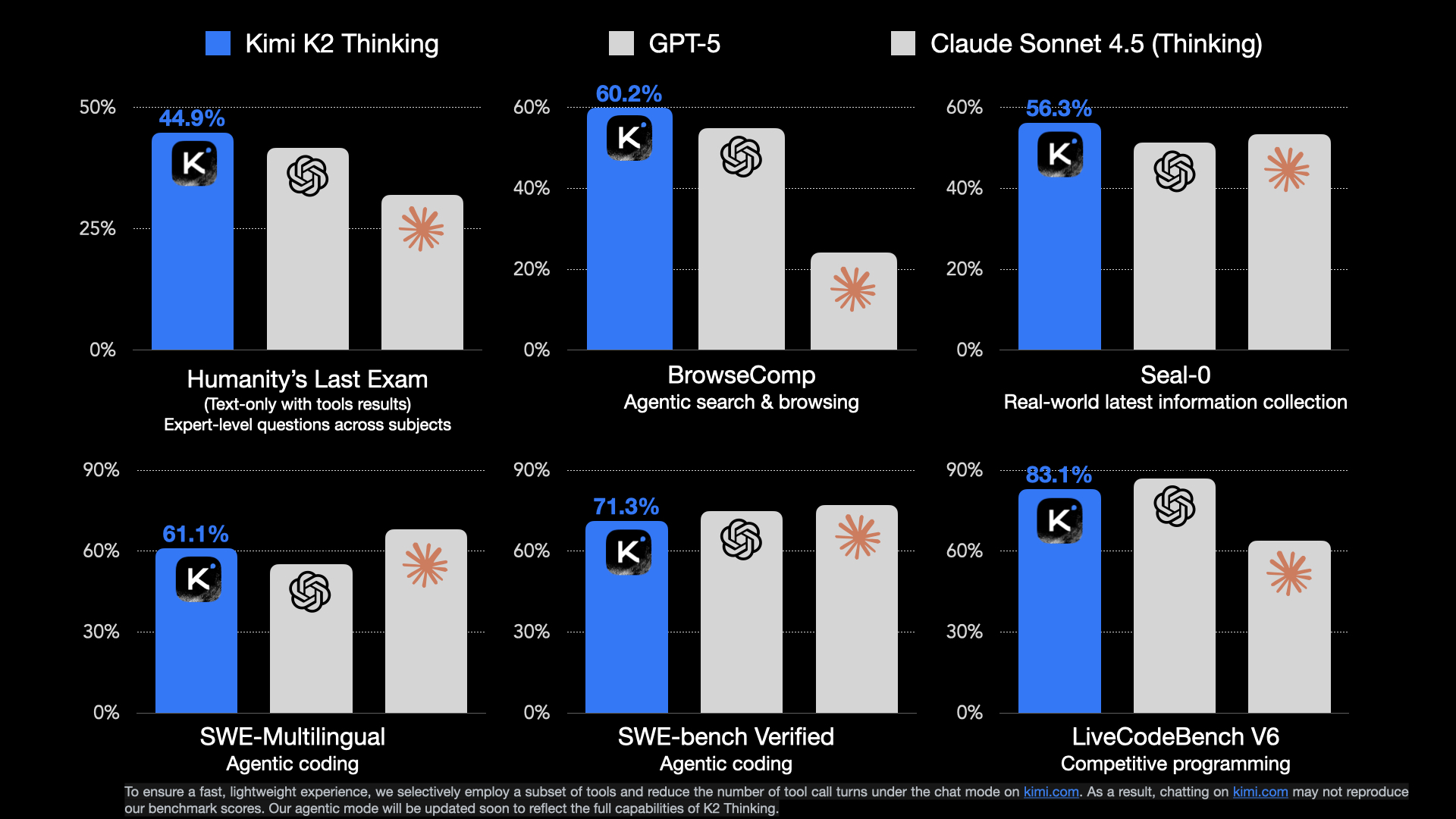
Is this another DeepSeek moment? Open-source passing closed-source again Should we expect this every couple months now?Kimi.ai: 🚀 Hello, Kimi K2 Thinking! The Open-Source Thinking Agent Model is here. 🔹 SOTA on HLE (44.9%) and BrowseComp (60.2%) 🔹 Executes up to 200 – 300 sequential tool calls without human interference 🔹 Excels in reasoning, agentic search, and coding 🔹 256K context window Built Link: https://x.com/Kimi_Moonshot/status/1986449512538513505
Hugging Face science team blog posts on training LLMsJames Lucas: Bibliothèque Méjanes, a library in France Link: https://x.com/JamesLucasIT/status/1986132835309068646

we're doing something special and intimate at @SlushHQ in 2 weeks with a couple of teams you might know :) some infos at: https://platform.slush.org/public/slush25/activities/edc8df18-9646-4558-887e-eb3cf8b6c19c?ref=twitter

Thomas Wolf: Despite all the big funding rounds and flashy demos in US robotics, K-Scale’s inability to raise more money should worry us We're at risk of replaying the LLM story all over again in robotics: - Chinese companies are going open-source and collaborating across the value chain Link: https://x.com/Thom_Wolf/status/1986011164132696181

Despite all the big funding rounds and flashy demos in US robotics, K-Scale’s inability to raise more money should worry us We're at risk of replaying the LLM story all over again in robotics: - Chinese companies are going open-source and collaborating across the value chain (from EV suppliers to downstream integrators) - most US teams are going full-stack proprietary, closed-source, all in-house Guess which robots the next wave of US research labs and startups will actually be able to build on when they want to invent new algorithms or tackle unseen real-world use cases?Harrison Kinsley: K-scale cancels orders and refunds deposits for kbot. I thought all the VCs were excited about US-based robotics, what happen? Link: https://x.com/Sentdex/status/1985810689458569502

I like this direction a lot. As we get code writing increasingly automated we’ll want to move to higher level representations of code. a lot of UX to invent hereCognition: Introducing Codemaps in @windsurf! powered by SWE-1.5 and Sonnet 4.5 “Your code is your understanding of the problem you’re exploring. So it’s only when you have your code in your head that you really understand the problem.” — @paulg Link: https://x.com/cognition/status/1985755284527010167
RT Lewis Tunstall Or ... you could just host them on http://hf.coAnthropic: Even when new AI models bring clear improvements in capabilities, deprecating the older generations comes with downsides. An update on how we’re thinking about these costs, and some of the early steps we’re taking to mitigate them: https://www.anthropic.com/research/deprecation-commitments Link: https://x.com/AnthropicAI/status/1985752012189728939

Monday morning read: a fascinating deep dive in recent Chinese chips developments as well as the coming co-evolution with LLM builders fresh analysis from the HF team => https://huggingface.co/blog/huggingface/shifting-compute-landscape

saying it way better than I doJay Alammar: The incredible work the @huggingface does in the open truly charts a path towards a post-scarcity future that includes everyone in the fruits of AI. Link: https://x.com/JayAlammar/status/1984273218568696014

RT Sasha Rush The work Hugging Face does continues to be incredible. Putting in serious effort to make these topics accessible and detailed. https://huggingface.co/spaces/HuggingFaceTB/smol-training-playbook#introduction