Jerry Liu
About
document OCR + workflows @llama_index. cofounder/CEO Careers: https://t.co/EUnMNmb4DZ Enterprise: https://t.co/Ht5jwxRU13
Platforms
Content History
RT LlamaIndex 🦙 Chart OCR just got a major upgrade with our new experimental "agentic chart parsing" feature in LlamaParse 📈🧪 Most LLMs struggle with converting charts to precise numerical data, so we've created an experimental a system that follows contours in line charts and extracts values. Automate chart analysis without spending hours manually correcting extracted values. Try it now in LlamaParse: https://cloud.llamaindex.ai/?utm_source=socials&utm_medium=li_social

One of the biggest use cases for agentic document automation is insurance underwriting ✍️ Underwriting depends on processing *massive* volumes of unstructured documents, from medical reports, scanned forms, and way more. It's also historically been a massively manual process. We're super excited to feature this case study with Pathwork AI - Pathwork is hyperfocused on building underwriting agents for life insurance. They're able to use LlamaCloud as a core module in order to process the massive volume of docs, from medical documentation to carrier guidelines. Check it out: https://www.llamaindex.ai/customers/pathwork-automates-information-extraction-from-medical-records-and-underwriting-guidelines-with?utm_source=socials&utm_medium=li_social LlamaCloud: https://cloud.llamaindex.ai/LlamaIndex 🦙: See how @pathwork scaled their life insurance document processing from 5,000 to 40,000 pages per week using LlamaParse. 📄 Process complex medical records, lab results, and decades-old scanned PDFs with 8x improved throughput 🤖 Automatically extract and index carrier Link: https://x.com/llama_index/status/1988290671279829204


RT LlamaIndex 🦙 See how @pathwork scaled their life insurance document processing from 5,000 to 40,000 pages per week using LlamaParse. 📄 Process complex medical records, lab results, and decades-old scanned PDFs with 8x improved throughput 🤖 Automatically extract and index carrier underwriting guidelines to keep risk rules current ⚡ Replace fragile, manual pipelines with robust automation that handles everything from digital forms to 1970s faded scans 🎯 Free up engineering time from maintenance to focus on building new product features @pathwork's Case Underwriter, Knowledge Assistant, and Pre-App Manager products all rely on transforming unstructured insurance documentation into structured data for faster decision-making. By integrating LlamaParse, they eliminated bottlenecks that were directly limiting customer growth and built future-proof infrastructure that automatically improves over time. Read the full case study: https://www.llamaindex.ai/customers/pathwork-automates-information-extraction-from-medical-records-and-underwriting-guidelines-with?utm_source=socials&utm_medium=li_social
We've gotten super, super deep in the wonderful world of document OCR through the history of @llama_index - and we'd love to share it with you! 🌟 1. There's a lot of benefits to "traditional" methods of reading the PDF binary for fast, cheap parsing. 2. You can use LLMs in the loop for general reading order reconstruction. 3. VLMs are obviously useful and we've benchmarked every frontier model there is out there to give high quality results over the most complex pages within our pipeline. State-of-the-art document parsing is super important for building agentic automation over any set of docs, and we've invested in it for the past 2 years. Register here: https://landing.llamaindex.ai/beynd-ocr-how-ai-agents-parse-complex-docs?utm_source=socials&utm_medium=li_socialLlamaIndex 🦙: We probably shouldn't tell you how to build your own document parsing agents, but we will 😮. AI agents are transforming how we handle messy, real-world documents that break traditional OCR systems. Join our live webinar on December 4th at 9 AM PST where the LlamaParse team Link: https://x.com/llama_index/status/1986810928713855235


We're partnering with @browserbase, @braintrust, @modal for an awesome afterparty at re:invent - come join us!LlamaIndex 🦙: There are Vegas parties and there is Late Shift 🎉 Join us for an exclusive re:Invent afterparty that brings together the best minds in AI and tech for a night you won't forget. 🍸 Cocktails and disco balls at Diner Ross Steakhouse in The LINQ 🤖 Connect with the teams behind Link: https://x.com/llama_index/status/1988003781448266141

RT LlamaIndex 🦙 There are Vegas parties and there is Late Shift 🎉 Join us for an exclusive re:Invent afterparty that brings together the best minds in AI and tech for a night you won't forget. 🍸 Cocktails and disco balls at Diner Ross Steakhouse in The LINQ 🤖 Connect with the teams behind @browserbase, @braintrust, @modal_labs, and LlamaIndex 🌙 Late-night tech conversations when the conference sessions end 🎟️ Limited spots with approval-required registration We're teaming up with our friends at @browserbase, @usebraintrust, and @modal_labs to host the most fun you'll have all conference. After your evening sessions, meet us for cocktails, networking, and the kind of tech chatter that makes re:Invent legendary. RSVP now - spots are limited: https://luma.com/lateshift
I’m very interested in seeing how many bits and pieces of finance work we can fully automate with agents. I built a multi-step agentic workflow to automate SEC document understanding👇 Given an SEC filing (10K, 10Q, 8K), use our agent classify module to determine what type it is, and route it to the right schema for document extraction (powered by LlamaExtract) Powered by LlamaCloud and LlamaAgents - it’s a full code-based orchestration layer over LLM capabilities. Simple Repo + file: https://github.com/jerryjliu/classify_extract_sec/blob/main/src/extraction_review_tmp5_classify_sec/process_file.py LlamaAgents: https://developers.llamaindex.ai/python/llamaagents/overview/ LlamaCloud: https://cloud.llamaindex.ai/
Build an agentic finance workflow over your inbox 📤 We’ve created a template that shows you how to automatically classify and process invoices/expense attachments as emails come in, with super high accuracy. Uses state-of-the-art OCR available in LlamaParse, wrapped in a LlamaAgents workflow. Shoutout @itsclelia for this example! Repo: https://github.com/AstraBert/financial-team-agent LlamaCloud: https://cloud.llamaindex.ai/login?redirect=%2F%3Futm_source%3Dtwitter%26utm_medium%3Dli_socialLlamaIndex 🦙: Trigger your agent workflows directly from your inbox, using our LlamaAgents and @resend webhooks📧 In this demo, we built a system that: 👉 Receives emails with documents attached 👉 Classifies the attachments as either invoices or expenses using LlamaClassify 👉 Extracts the Link: https://x.com/llama_index/status/1986847428272857356
RT LlamaIndex 🦙 Trigger your agent workflows directly from your inbox, using our LlamaAgents and @resend webhooks📧 In this demo, we built a system that: 👉 Receives emails with documents attached 👉 Classifies the attachments as either invoices or expenses using LlamaClassify 👉 Extracts the relevant information through LlamaExtract 👉 Writes an email reply and sends it back to the user All of this is packaged as an agent workflow and deployed to the cloud through our LlamaAgents!🚀 🦙 Get started with all our LlamaCloud services now: https://cloud.llamaindex.ai?utm_source=twitter&utm_medium=li_social 📚 Learn more about our agent workflows: https://developers.llamaindex.ai/python/llamaagents/overview?utm_source=twitter&utm_medium=li_social ⭐ Star the repo on GitHub: http://github.com/AstraBert/financial-team-agent
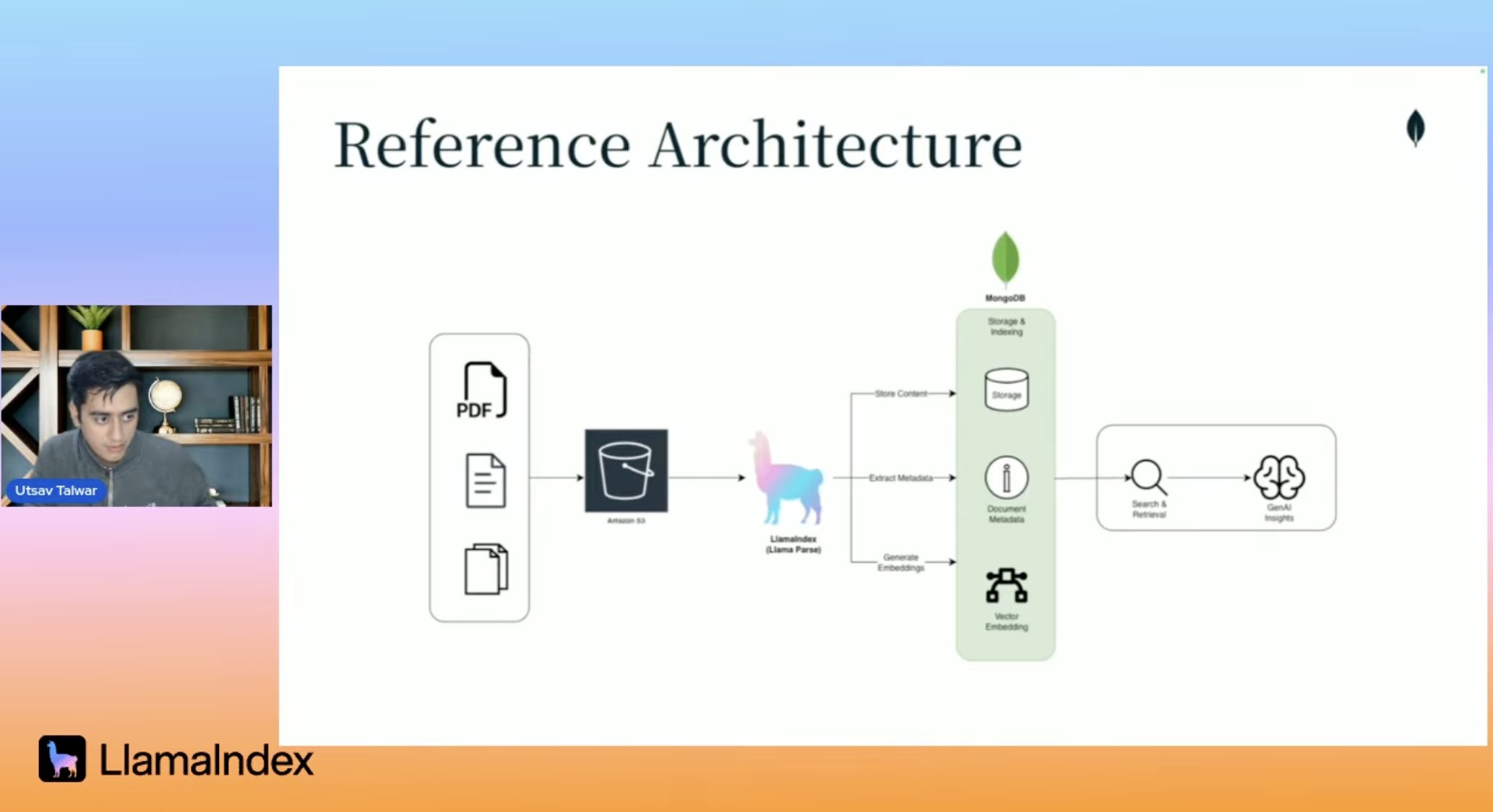
For the first time in human history, you can: 1️⃣ Take a bucket of docs/PDFs 🪣📑 2️⃣ Make sense of it 3️⃣ Extract insights / search over it with super high accuracy with effectively 0 humans involved. This is a neat joint stack we copublished with @MongoDB, check it out! https://youtube.com/watch?v=5mEPkPtoNyYLlamaIndex 🦙: Last week, we teamed up with @MongoDB to break down one of the most persistent challenges in production AI systems: turning messy, real-world documents into reliable insights. Enterprise documents don't come in neat, uniform packages. Invoices, SEC filings, reports—they all have Link: https://x.com/llama_index/status/1986117341911130163

Build an AI agent to automate your finance team’s entire invoice/expense workflow! 🧾 @TuanaCelik has built a fantastic example that shows you how to construct an agentic workflow that can triage incoming emails + attachments, detect whether it’s an invoice or expense, and process it accordingly. It uses our core agentic classification / extraction capabilities under the hood in LlamaCloud, and is backed by @llama_index workflows. Check it out: https://github.com/run-llama/workflows-py/blob/main/examples/document_agents/finance_triage_agent.ipynbLlamaIndex 🦙: Here's a common scenario: Your finance team gets emails all day with invoices from partners and expense reports from employees. Each one needs different handling. Invoices need acknowledgment and payment scheduling. Expenses need budget validation before approval etc. In this Link: https://x.com/llama_index/status/1986476949687140503


RT LlamaIndex 🦙 We probably shouldn't tell you how to build your own document parsing agents, but we will 😮. AI agents are transforming how we handle messy, real-world documents that break traditional OCR systems. Join our live webinar on December 4th at 9 AM PST where the LlamaParse team reveals industry secrets for parsing complex documents: 📋 Blueprint for building next-generation document parsing workflows using agents instead of OCR alone 🔧 Practical strategies for handling handwriting, rotated scans, nested tables, and visually dense layouts 🤖 Latest LlamaCloud capabilities showing how vision language models automate extraction from previously unparseable PDFs, forms, and images ⚡ When to apply each component in your parsing pipeline and why it matters We'll show you how to move beyond simple text extraction to actually automate understanding of documents with multi-column layouts, embedded charts, skewed scans, and tables within tables. Register now: https://landing.llamaindex.ai/beynd-ocr-how-ai-agents-parse-complex-docs?utm_source=socials&utm_medium=li_social
Our new bounding box approach in LlamaParse gives you clean bounding boxes while preserving clean reading order of the text through agentic reconstruction. The issue with traditional parsing methods is that the quality of the output is directly dependent on the layout detector - if the predicted boxes are wrong / in the wrong sequence, then your output is garbled. Here we use LLMs to reconstruct the entire semantic flow of the text, but still allow bounding box processing in parallel for additional metadata! Now available in LlamaParse: https://cloud.llamaindex.ai/

RT LlamaIndex 🦙 Here's a common scenario: Your finance team gets emails all day with invoices from partners and expense reports from employees. Each one needs different handling. Invoices need acknowledgment and payment scheduling. Expenses need budget validation before approval etc. In this example we build an agent that automatically triages incoming emails with attachments, extracts the right information, and takes appropriate action. Our approach uses three of our tools working together: 1️⃣ LlamaClassify handles the first decision point. It looks at each attachment and determines: is this an invoice that needs to be paid out to a partner, or an expense that needs reimbursement? It also provides reasoning for the decision. 2️⃣ LlamaExtract does the heavy lifting on data extraction. We create two specialized agents with different schemas for invoices vs expenses. 3️⃣ Agent Workflows orchestrates the entire process. It connects classification to extraction to business logic: in this case, checking expenses against a budget threshold and generating appropriate email responses via LLM. Classify incoming documents → extract relevant data → apply business rules → take action. Need to add a new document type? Add a classification rule and an extraction schema. Need different business logic? Modify the workflow steps. The components stay the same. Check out the full example: https://github.com/run-llama/workflows-py/blob/main/examples/document_agents/finance_triage_agent.ipynb
grep AND semantic search is all you need The fact that coding agents can access CLI commands makes them way better at search than standard retrieval. with grep/read/cat operations you can dynamically load different chunks of data and traverse complex directories. Obviously the even better answer is to just combine the two. Combine grep with semantic search. If you want to DIY this, check out `semtools`! We've built a simple lightweight, index-free engine that lets you run semantic search over any directory as a CLI command. Easily give it to your favorite coding agent e.g. Claude Code / Cursor to run. https://github.com/run-llama/semtoolsCursor: Semantic search improves our agent's accuracy across all frontier models, especially in large codebases where grep alone falls short. Learn more about our results and how we trained an embedding model for retrieving code. Link: https://x.com/cursor_ai/status/1986124270548709620
semtools is the easiest way to let your Claude Code / Cursor become an analyst over 1k+ PDF docs. It just adds two CLI commands: `parse`, `search`. Install it to ~/.zshrc and add it to your http://CLAUDE.md. Any coding agent can still choose to use grep, but now they get access to semantic search. Check it out: https://github.com/run-llama/semtools Blog: https://www.llamaindex.ai/blog/semtools-are-coding-agents-all-you-needLogan Markewich: Cursor put out a blog today stating that semantic search beats grep Semantic search doesn't have to be complicated, and thats exactly why I built SemTools -- to provide agents with a "fuzzy semantic grep search" Semtools https://github.com/run-llama/semtools Blog https://cursor.com/blog/semsearch Link: https://x.com/LoganMarkewich/status/1986231594072613333
RT Logan Markewich Cursor put out a blog today stating that semantic search beats grep Semantic search doesn't have to be complicated, and thats exactly why I built SemTools -- to provide agents with a "fuzzy semantic grep search" Semtools https://github.com/run-llama/semtools Blog https://cursor.com/blog/semsearch
RT LlamaIndex 🦙 Last week, we teamed up with @MongoDB to break down one of the most persistent challenges in production AI systems: turning messy, real-world documents into reliable insights. Enterprise documents don't come in neat, uniform packages. Invoices, SEC filings, reports—they all have irregular layouts, embedded tables, images, and context that traditional text extraction just can't handle. In this session, we walked through a complete document processing workflow that works at scale: LlamaParse acts as an agentic parsing tool that understands document structure—not just text extraction. It handles complex layouts, preserves table formatting, and extracts images with context. It outputs clean markdown that LLMs can work with. The architecture is : S3 → LlamaParse → MongoDB Atlas → LLM. The recording is up now: https://www.youtube.com/watch?v=5mEPkPtoNyY
RT LlamaIndex 🦙 MavenBio transformed complex scientific visuals in biopharma documents into searchable, analyzable intelligence using LlamaParse. Before LlamaParse, MavenBio's AI platform could process text-heavy documents but missed critical insights locked in charts, figures, and conference posters that drive real biopharma decisions. 🔬 Visual content parsing: Conference posters, regulatory filings, and scientific publications with complex diagrams now become fully searchable 📊 10x-20x faster workflows: Users can run comparative trial assessments and opportunity prioritization with unprecedented speed and depth 🎯 Enhanced accuracy: Visual context integration improved the precision of structured analyses across their platform ⚡ Engineering focus: Team reallocated resources from building parsing infrastructure to core product innovation "LlamaParse bridges the gap between static visual data and structured language," says @bernardffaucher, Founding Senior Backend Engineer at MavenBio. The webhook-based asynchronous processing scaled their throughput while maintaining low latency across their always-on ingestion pipeline. Read the full case study: https://www.llamaindex.ai/customers/maven-bio-turns-the-unstructured-world-of-complex-scientific-visuals-into-intelligence-with?utm_source=socials&utm_medium=li_social

Haiku 4.5 is better than GPT-5 at document OCR over tables 📋 Better reasoning doesn’t correlate to visual understanding 💡. I fed the NYC MTA timetable as screenshots into both GPT-5 and Haiku 4.5. - (Left) GPT-5 ignores the spaces between table values - (Right) Haiku almost perfectly reconstructs the table including spaces in between. The extra columns don’t materially impact the correctness of the results. Haiku is shaping up to be a great lightweight contender for document parsing. You can play with it and other models within LlamaCloud! LlamaCloud: https://cloud.llamaindex.ai/


RT LlamaIndex 🦙 Augment your LlamaIndex agent workflows with memory and persistent states: Check out @itsclelia's talk at @qdrant_engine Vector Space Day to learn how to build context-rich AI systems leveraging vector search and workflow engineering. Take a look at the YT video: https://youtu.be/CDyFukgpayY Learn more about LlamaIndex agent workflows: https://developers.llamaindex.ai/python/llamaagents/overview?utm_source=twitter&utm_medium=li_social
