Andrej Karpathy
简介
Building @EurekaLabsAI. Previously Director of AI @ Tesla, founding team @ OpenAI, CS231n/PhD @ Stanford. I like to train large deep neural nets.
平台
内容历史
I am unreasonably excited about self-driving. It will be the first technology in many decades to visibly terraform outdoor physical spaces and way of life. Less parked cars. Less parking lots. Much greater safety for people in and out of cars. Less noise pollution. More space reclaimed for humans. Human brain cycles and attention capital freed up from “lane following” to other pursuits. Cheaper, faster, programmable delivery of physical items and goods. It won’t happen overnight but there will be the era before and the era after.
Activity on karpathy/nanochat
karpathy closed a pull request in nanochat
karpathy closed a pull request in nanochat
View on GitHubI took delivery of a beautiful new shiny HW4 Tesla Model X today, so I immediately took it out for an FSD test drive, a bit like I used to do almost daily for 5 years. Basically... I'm amazed - it drives really, really well, smooth, confident, noticeably better than what I'm used to on HW3 (my previous car) and eons ahead of the version I remember driving up highway 280 on my first day at Tesla ~9 years ago, where I had to intervene every time the road mildly curved or sloped. (note this is v13, my car hasn't been offered the latest v14 yet) On the highway, I felt like a passenger in some super high tech Maglev train pod - the car is locked in the center of the lane while I'm looking out from Model X's higher vantage point and its panoramic front window, listening to the (incredible) sound system, or chatting with Grok. On city streets, the car casually handled a number of tricky scenarios that I remember losing sleep over just a few years ago. It negotiated incoming cars in tight lanes, it gracefully went around construction and temporarily in-lane stationary cars, it correctly timed tricky left turns with incoming traffic from both sides, it gracefully gave way to the car that went out of order in the 4-way stop sign, it found a way to squeeze into a bumper to bumper traffic to make its turn, it overtook the bus that was loading passengers but still stopped for the stop sign that was blocked by the bus, and at the end of the route it circled around a parking lot, found a spot and... parked. Basically a flawless drive. For context, I'm used to going out for a brief test drive around the neighborhood to return with 20 clips of things that could be improved. It's new for me to do just that and exactly like I used to, but come back with nothing. Perfect drive, no notes. I expect there's still more work for the team in the long march of 9s, but it's just so cool to see that we're beyond finding issues on any individual ~1 hour drive around the neighborhood, you actua...
Activity on karpathy/nanochat
karpathy closed a pull request in nanochat
karpathy closed a pull request in nanochat
View on GitHubActivity on karpathy/nanochat
karpathy commented on pull request karpathy/nanochat#242
karpathy commented on pull request karpathy/nanochat#242
View on GitHubRT Together AI 📄New Guide: Running nanochat on instant clusters! Train and inference @karpathy's end-to-end ChatGPT clone on Together’s on-demand GPU clusters — and learn how to: ➡️Train nanochat ➡️Nanochat inference ➡️Iterate to see if you can speed up training!

Activity on karpathy/nanochat
karpathy closed a pull request in nanochat
karpathy closed a pull request in nanochat
View on GitHubActivity on karpathy/nanochat
karpathy closed an issue in nanochat
karpathy closed an issue in nanochat
View on GitHubActivity on karpathy/nanochat
karpathy closed a pull request in nanochat
karpathy closed a pull request in nanochat
View on GitHubActivity on karpathy/nanochat
karpathy closed a pull request in nanochat
karpathy closed a pull request in nanochat
View on GitHubActivity on karpathy/nanochat
karpathy commented on pull request karpathy/nanochat#205
karpathy commented on pull request karpathy/nanochat#205
View on GitHubBeautiful technical debugging detective longread that starts with a suspicious loss curve and ends all the way in the Objective-C++ depths of PyTorch MPS backend of addcmul_ that silently fails on non-contiguous output tensors. I wonder how long before an LLM can do all of this.Elana Simon: New blog post: The bug that taught me more about PyTorch than years of using it started with a simple training loss plateau... ended up digging through optimizer states, memory layouts, kernel dispatch, and finally understanding how PyTorch works! Link: https://x.com/ElanaPearl/status/1981389648695025849

Last night I taught nanochat d32 how to count 'r' in strawberry (or similar variations). I thought this would be a good/fun example of how to add capabilities to nanochat and I wrote up a full guide here: https://github.com/karpathy/nanochat/discussions/164 This is done via a new synthetic task `SpellingBee` that generates examples of a user asking for this kind of a problem, and an ideal solution from an assistant. We then midtrain/SFT finetune on these to endow the LLM with the capability, or further train with RL to make it more robust. There are many details to get right especially at smaller model sizes and the guide steps through them. As a brief overview: - You have to ensure diversity in user prompts/queries - For small models like nanochat especially, you have to be really careful with the tokenization details to make the task easy for an LLM. In particular, you have to be careful with whitespace, and then you have to spread the reasoning computation across many tokens of partial solution: first we standardize the word into quotes, then we spell it out (to break up tokens), then we iterate and keep an explicit counter, etc. - I am encouraging the model to solve the model in two separate ways: a manual way (mental arithmetic in its head) and also via tool use of the Python interpreter that nanochat has access to. This is a bit "smoke and mirrors" because every solution atm is "clean", with no mistakes. One could either adjust the task to simulate mistakes and demonstrate recoveries by example, or run RL. Most likely, a combination of both works best, where the former acts as the prior for the RL and gives it things to work with. If nanochat was a much bigger model, you'd expect or hope for this capability to more easily "pop out" at some point. But because nanochat d32 "brain" is the size of a ~honeybee, if we want it to count r's in strawberry, we have to do it by over-representing it in the data, to encourage the model to learn it earlier. But it works...

I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter. The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language person) is whether pixels are better inputs to LLMs than text. Whether text tokens are wasteful and just terrible, at the input. Maybe it makes more sense that all inputs to LLMs should only ever be images. Even if you happen to have pure text input, maybe you'd prefer to render it and then feed that in: - more information compression (see paper) => shorter context windows, more efficiency - significantly more general information stream => not just text, but e.g. bold text, colored text, arbitrary images. - input can now be processed with bidirectional attention easily and as default, not autoregressive attention - a lot more powerful. - delete the tokenizer (at the input)!! I already ranted about how much I dislike the tokenizer. Tokenizers are ugly, separate, not end-to-end stage. It "imports" all the ugliness of Unicode, byte encodings, it inherits a lot of historical baggage, security/jailbreak risk (e.g. continuation bytes). It makes two characters that look identical to the eye look as two completely different tokens internally in the network. A smiling emoji looks like a weird token, not an... actual smiling face, pixels and all, and all the transfer learning that brings along. The tokenizer must go. OCR is just one of many useful vision -> text tasks. And text -> text tasks can be made to be vision ->text tasks. Not vice versa. So many the User message is images, but the decoder (the Assistant response) remains text. It's a lot less obvious how to output pixels realistically... or if you'd want to. Now I have to also fight the urge to side quest an image-input-only version of nanochat...vLLM: 🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context c...



Nice, short post illustrating how simple text (discrete) diffusion can be. Diffusion (i.e. parallel, iterated denoising, top) is the pervasive generative paradigm in image/video, but autoregression (i.e. go left to right bottom) is the dominant paradigm in text. For audio I've seen a bit of both. A lot of diffusion papers look a bit dense but if you strip the mathematical formalism, you end up with simple baseline algorithms, e.g. something a lot closer to flow matching in continuous, or something like this in discrete. It's your vanilla transformer but with bi-directional attention, where you iteratively re-sample and re-mask all tokens in your "tokens canvas" based on a noise schedule until you get the final sample at the last step. (Bi-directional attention is a lot more powerful, and you get a lot stronger autoregressive language models if you train with it, unfortunately it makes training a lot more expensive because now you can't parallelize across sequence dim). So autoregression is doing an `.append(token)` to the tokens canvas while only attending backwards, while diffusion is refreshing the entire token canvas with a `.setitem(idx, token)` while attending bidirectionally. Human thought naively feels a bit more like autoregression but it's hard to say that there aren't more diffusion-like components in some latent space of thought. It feels quite possible that you can further interpolate between them, or generalize them further. And it's a component of the LLM stack that still feels a bit fungible. Now I must resist the urge to side quest into training nanochat with diffusion.Nathan Barry: BERT is just a Single Text Diffusion Step! (1/n) When I first read about language diffusion models, I was surprised to find that their training objective was just a generalization of masked language modeling (MLM), something we’ve been doing since BERT from 2018. The first Link: https://x.com/nathanbarrydev/status/1980316126572658843
My pleasure to come on Dwarkesh last week, I thought the questions and conversation were really good. I re-watched the pod just now too. First of all, yes I know, and I'm sorry that I speak so fast :). It's to my detriment because sometimes my speaking thread out-executes my thinking thread, so I think I botched a few explanations due to that, and sometimes I was also nervous that I'm going too much on a tangent or too deep into something relatively spurious. Anyway, a few notes/pointers: AGI timelines. My comments on AGI timelines looks to be the most trending part of the early response. This is the "decade of agents" is a reference to this earlier tweet https://x.com/karpathy/status/1882544526033924438 Basically my AI timelines are about 5-10X pessimistic w.r.t. what you'll find in your neighborhood SF AI house party or on your twitter timeline, but still quite optimistic w.r.t. a rising tide of AI deniers and skeptics. The apparent conflict is not: imo we simultaneously 1) saw a huge amount of progress in recent years with LLMs while 2) there is still a lot of work remaining (grunt work, integration work, sensors and actuators to the physical world, societal work, safety and security work (jailbreaks, poisoning, etc.)) and also research to get done before we have an entity that you'd prefer to hire over a person for an arbitrary job in the world. I think that overall, 10 years should otherwise be a very bullish timeline for AGI, it's only in contrast to present hype that it doesn't feel that way. Animals vs Ghosts. My earlier writeup on Sutton's podcast https://x.com/karpathy/status/1973435013875314729 . I am suspicious that there is a single simple algorithm you can let loose on the world and it learns everything from scratch. If someone builds such a thing, I will be wrong and it will be the most incredible breakthrough in AI. In my mind, animals are not an example of this at all - they are prepackaged with a ton of intelligence by evolution and the learning...
nanochat d32, i.e. the depth 32 version that I specced for $1000, up from $100 has finished training after ~33 hours, and looks good. All the metrics go up quite a bit across pretraining, SFT and RL. CORE score of 0.31 is now well above GPT-2 at ~0.26. GSM8K went ~8% -> ~20%, etc. So that's encouraging. The model is pretty fun to talk to, but judging from some early interactions I think people have a little bit too much expectation for these micro models. There is a reason that frontier LLM labs raise billions to train their models. nanochat models cost $100 - $1000 to train from scratch. The $100 nanochat is 1/1000th the size of GPT-3 in parameters, which came out 5 years ago. So I urge some perspective. Talking to micro models you have to imagine you're talking to a kindergarten child. They say cute things, wrong things, they are a bit confused, a bit naive, sometimes a little non-sensical, they hallucinate a ton (but it's amusing), etc. Full detail/report on this run is here: https://github.com/karpathy/nanochat/discussions/8 And I pushed the new script run1000 sh to the nanochat repo if anyone would like to reproduce. Totally understand if you'd like to spend $1000 on something else :D If you like, I am currently hosting the model so you can talk to it on a webchat as you'd talk to ChatGPT. I'm not going to post the URL here because I'm afraid it will get crushed. You'll have to look for it if you care enough. I'm also attaching a few funny conversations I had with the model earlier into the image, just to give a sense. Next up, I am going to do one pass of tuning and optimizing the training throughput, then maybe return back to scaling and maybe training the next tier of a bigger model.

Every company needs a DM POC - someone high up who you can just DM the most obvious things and who shortcuts the PM hierarchy.
For your professional programming do you use mostly:
Animals vs Ghosts
Finally had a chance to listen through this Dwarkesh pod with Sutton, which was interesting and amusing. As background, Sutton's "The Bitter Lesson" has become a bit of biblical text in frontier LLM circles. Researchers routinely talk about and ask whether this or that approach or idea is sufficiently "bitter lesson pilled" (meaning arranged so that it benefits from added computation for free) as a proxy for whether it's going to work or worth even pursuing. The underlying assumption being that LLMs are of course highly "bitter lesson pilled" indeed, just look at LLM scaling laws where if you put compute on the x-axis, number go up and to the right. So it's amusing to see that Sutton, the author of the post, is not so sure that LLMs are "bitter lesson pilled" at all. They are trained on giant datasets of fundamentally human data, which is both 1) human generated and 2) finite. What do you do when you run out? How do you prevent a human bias? So there you have it, bitter lesson pille...
Vibe coding MenuGen
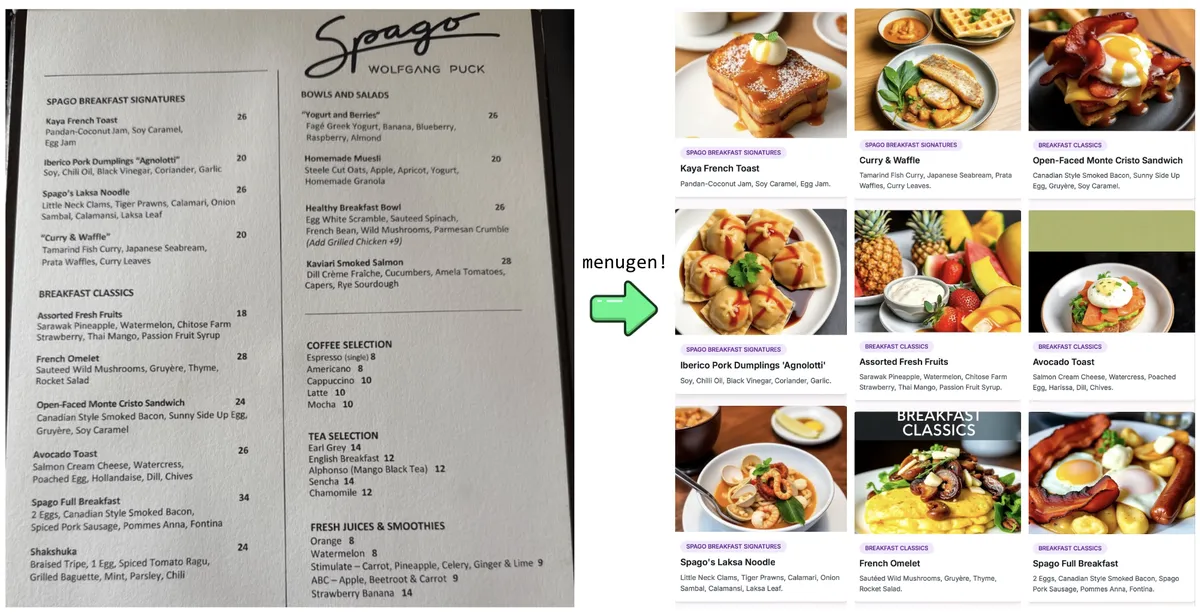
Very often, I sit down at a restaurant, look through their menu, and feel... kind of stuck. What is Pâté again? What is a Tagine? Cavatappi... that's a pasta right? Sweetbread sounds delicious (I have a huge sweet tooth). It can get really out of hand sometimes. "Confit tubers folded with matured curd and finished with a beurre noisette infusion." okay so... what is this exactly? I've spent so much of my life googling pictures of foods that when the time came to attend a recent vibe coding hackathon, I knew it was the perfect opportunity to finally build the app I always wanted, but could nowhere find. And here it is in flesh, I call it... 🥁🥁🥁 ... MenuGen: MenuGen is super simple. You take a picture of a menu and it generates images for all the menu items. It visualizes the menu. Obviously it's not exactly what you will be served in that specific restaurant, but it gives you the basic idea: Some of these dishes are salads, this is a fish, this is a soup, etc. I found it so helpf...
Power to the people: How LLMs flip the script on technology diffusion

Transformative technologies usually follow a top-down diffusion path: originating in government or military contexts, passing through corporations, and eventually reaching individuals - think electricity, cryptography, computers, flight, the internet, or GPS. This progression feels intuitive, new and powerful technologies are usually scarce, capital-intensive, and their use requires specialized technical expertise in the early stages. So it strikes me as quite unique and remarkable that LLMs display a dramatic reversal of this pattern - they generate disproportionate benefit for regular people, while their impact is a lot more muted and lagging in corporations and governments. ChatGPT is the fastest growing consumer application in history, with 400 million weekly active users who use it for writing, coding, translation, tutoring, summarization, deep research, brainstorming, etc. This isn't a minor upgrade to what existed before, it is a major multiplier to an individual's power leve...
Finding the Best Sleep Tracker

About 2 months ago I stumbled by this Bryan Johnson video on How I FIXED My Terrible Sleep - 10 Habits. I resolved that day to listen to Bryan and try to improve my sleep. But before we can improve it, first - how should we measure it? Bryan Johnson seems to use Whoop, but at that time I only had my Apple Watch (coupled with one of the popular sleep apps - AutoSleep). And then a long time ago I used and liked Oura. And I also had an order in for the new and fancy 8Sleep Pod 4 Ultra, which I was aware offers some sleep tracking too. So I found myself in a bit of a pickle - which one should I pick to track my sleep? And the answer of course is... to initiate a comprehensive tracking project to compare the 4 major candidates and find the. best. sleep. tracker. So that's what I did. This is me fully geared up and ready for bed: I've now gathered roughly 2 months of data. I kept the raw data in a simple spreadsheet, recording some of the basic measurements: the amount of sleep (Light, R...
The append-and-review note

A few words on an approach to note taking that I stumbled on and has worked for me quite well for many years. I call it the "append-and-review note". I find that this approach strikes a good balance of being super simple and easy to use but it also captures the majority of day-to-day note taking use cases. Data structure. I maintain one single text note in the Apple Notes app just called "notes". Maintaining more than one note and managing and sorting them into folders and recursive substructures costs way too much cognitive bloat. A single note means CTRL+F is simple and trivial. Apple does a good job of optional offline editing, syncing between devices, and backup. Append. Any time any idea or any todo or anything else comes to mind, I append it to the note on top, simply as text. Either when I'm on my computer when working, or my iPhone when on the go. I don't find that tagging these notes with any other structured metadata (dates, links, concepts, tags) is that useful and I don...
Digital hygiene

Every now and then I get reminded about the vast fraud apparatus of the internet, re-invigorating my pursuit of basic digital hygiene around privacy/security of day to day computing. The sketchiness starts with major tech companies who are incentivized to build comprehensive profiles of you, to monetize it directly for advertising, or sell it off to professional data broker companies who further enrich, de-anonymize, cross-reference and resell it further. Inevitable and regular data breaches eventually runoff and collect your information into dark web archives, feeding into a whole underground spammer / scammer industry of hacks, phishing, ransomware, credit card fraud, identity theft, etc. This guide is a collection of the most basic digital hygiene tips, starting with the most basic to a bit more niche. Password manager. Your passwords are your "first factor", i.e. "something you know". Do not be a noob and mint new, unique, hard passwords for every website or service that you si...
I love calculator

The other day I was randomly browsing in a bookstore and stumbled by Empire of the Sum: The Rise and Reign of the Pocket Calculator. As I was flipping through its pages, a realization dawned on me with some force: I... love... calculator. I don't mean as a physical device that you would wish to purchase and use today. I mean as a product of technology and a symbol of a kind of philosophy. Behold: The calculator is incredible. When operated with your fingers, it becomes a plugin for your brain, extending its computational capability in the domain of arithmetic. It makes you smarter. But even more incredible is the means by which this happens. The calculator is a fully self-contained physical artifact that has an almost zero "dependency footprint" on the rest of our technosphere. To perform its function it only requires light (thanks to its tiny solar panel on the front), and/or batteries, which are a universal commodity. You may choose to purchase the calculator with one single excha...