Sebastian Raschka
简介
ML/AI research engineer. Ex stats professor. Author of "Build a Large Language Model From Scratch" (https://t.co/O8LAAMRzzW) & reasoning (https://t.co/5TueQKx2Fk)
平台
内容历史
Activity on repository
rasbt pushed reasoning-from-scratch
rasbt pushed reasoning-from-scratch
View on GitHubActivity on repository
rasbt pushed reasoning-from-scratch
rasbt pushed reasoning-from-scratch
View on GitHubActivity on repository
rasbt pushed reasoning-from-scratch
rasbt pushed reasoning-from-scratch
View on GitHubActivity on rasbt/reasoning-from-scratch
rasbt contributed to rasbt/reasoning-from-scratch
rasbt contributed to rasbt/reasoning-from-scratch
View on GitHubActivity on rasbt/LLMs-from-scratch
rasbt opened a pull request in LLMs-from-scratch
rasbt opened a pull request in LLMs-from-scratch
View on GitHubActivity on repository
rasbt pushed reasoning-from-scratch
rasbt pushed reasoning-from-scratch
View on GitHubI often get questions from readers about how to read and get the most out of my book(s) on building LLMs from scratch. My advice is usually based on how I read technical books myself. This is not a one-size-fits-all approach, but I thought it may be useful to share: 1. Read the chapter preferably offline, away from the computer. Either classic physical form or at least on digital devices without internet. This really helps with focus time and minimizing distractions while reading. Highlighting or annotating confusing or interesting things is good, but I would not look things up at this stage. I also wouldn't run code at this stage. At least not yet. 2. On the second read-through, type up and run the code from the chapter. Copying code is tempting because retyping is a lot of work, but it usually helps me to think about the code a bit more (versus just glancing over it). If I get different results than in the book, I would check the book's GitHub repo and try the code from there. If I still get different results, I would try to see if it's due to different package versions, random seeds, CPU/CUDA, etc. If I then still can't find it out, asking the author would not be a bad idea (via book forum, public GitHub repo issues or discussions, and as a last resort, email) 3. After the second read-through and retyping the code, it's usually a good time to try the exercises to solidify my understanding. To check whether I actually understand the content and can work with it independently. 4. Go through the highlights and annotations. I would bookmark important learnings or takeaways, if relevant for a given project, in my notes documents. Often, I also look up additional references to read more about a topic of interest. Also, if I still have any questions that I feel are unanswered after my previous readthroughs and exercises, I would do an online search to find out more. 5. The previous steps were all about soaking up knowledge. Eventually, though, I somehow want to use...
Activity on rasbt/reasoning-from-scratch
rasbt opened a pull request in reasoning-from-scratch
rasbt opened a pull request in reasoning-from-scratch
View on GitHubActivity on repository
rasbt pushed reasoning-from-scratch
rasbt pushed reasoning-from-scratch
View on GitHubActivity on repository
rasbt pushed reasoning-from-scratch
rasbt pushed reasoning-from-scratch
View on GitHubActivity on repository
rasbt pushed reasoning-from-scratch
rasbt pushed reasoning-from-scratch
View on GitHubActivity on repository
rasbt pushed reasoning-from-scratch
rasbt pushed reasoning-from-scratch
View on GitHubActivity on repository
rasbt pushed reasoning-from-scratch
rasbt pushed reasoning-from-scratch
View on GitHubActivity on repository
rasbt pushed reasoning-from-scratch
rasbt pushed reasoning-from-scratch
View on GitHubActivity on rasbt/reasoning-from-scratch
rasbt contributed to rasbt/reasoning-from-scratch
rasbt contributed to rasbt/reasoning-from-scratch
View on GitHubActivity on repository
rasbt pushed reasoning-from-scratch
rasbt pushed reasoning-from-scratch
View on GitHubActivity on repository
rasbt pushed reasoning-from-scratch
rasbt pushed reasoning-from-scratch
View on GitHubActivity on repository
rasbt pushed reasoning-from-scratch
rasbt pushed reasoning-from-scratch
View on GitHubActivity on repository
rasbt pushed reasoning-from-scratch
rasbt pushed reasoning-from-scratch
View on GitHubActivity on repository
rasbt pushed reasoning-from-scratch
rasbt pushed reasoning-from-scratch
View on GitHubActivity on rasbt/reasoning-from-scratch
rasbt contributed to rasbt/reasoning-from-scratch
rasbt contributed to rasbt/reasoning-from-scratch
View on GitHubActivity on rasbt/LLMs-from-scratch
rasbt contributed to rasbt/LLMs-from-scratch
rasbt contributed to rasbt/LLMs-from-scratch
View on GitHubMy new field guide to alternatives to standard LLMs: Gated DeltaNet hybrids (Qwen3-Next, Kimi Linear), text diffusion, code world models, and small reasoning transformers. https://magazine.sebastianraschka.com/p/beyond-standard-llms

Beyond Standard LLMs
After I shared my Big LLM Architecture Comparison a few months ago, which focused on the main transformer-based LLMs, I received a lot of questions with respect to what I think about alternative approaches. (I also recently gave a short talk about that at the PyTorch Conference 2025, where I also promised attendees to follow up with a write-up of these alternative approaches). So here it is!
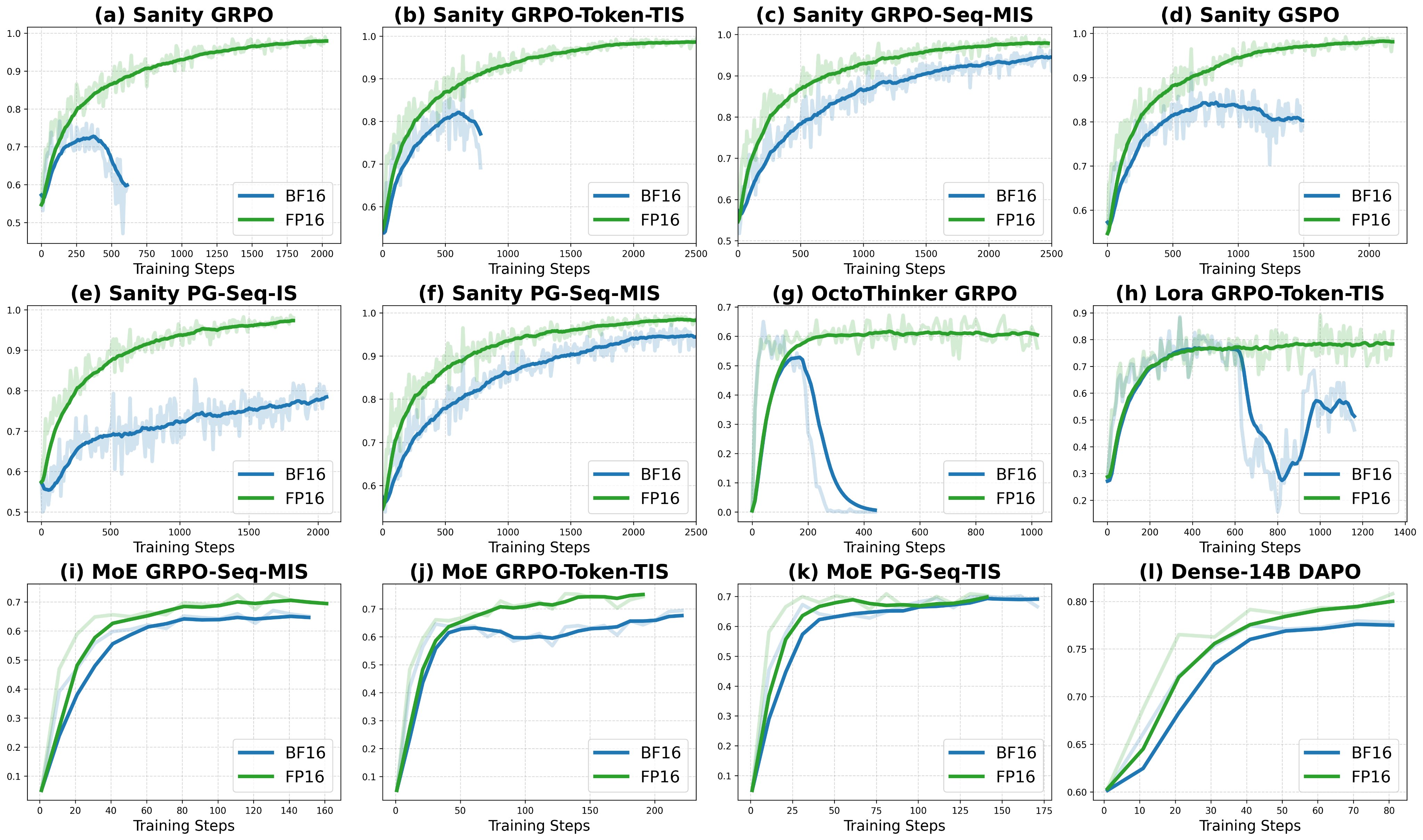
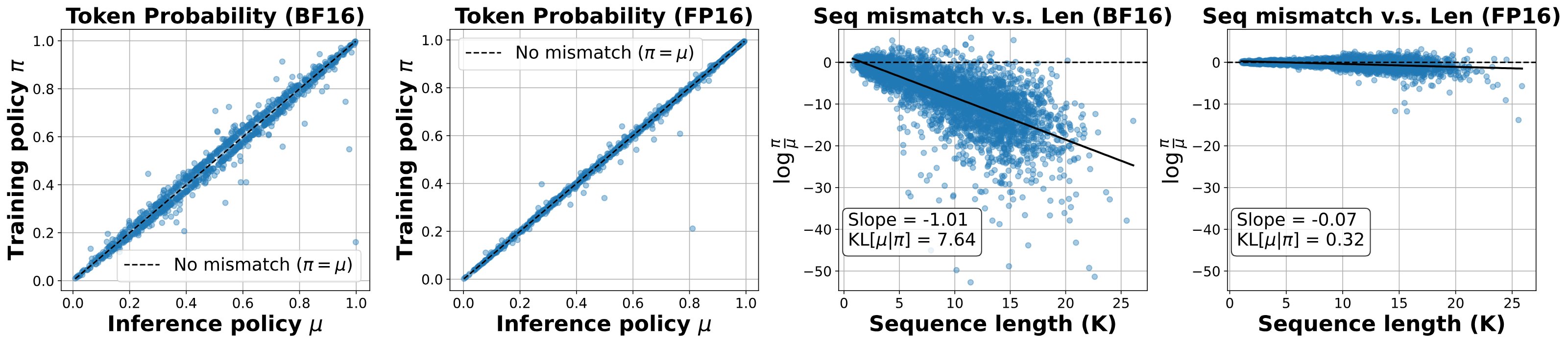
RT Benhao Huang It’s fascinating that FP16 can reduce training–inference mismatch in RL fine-tuning. Out of curiosity, I tried the same precision swap on the Tiny Recursive Model (TRM) @jm_alexia, which iterates hidden states to reason over inputs. The outcome was different: under FP16, training stalled after a few hundred steps and gradients vanished. Not too surprising in hindsight. Precision choice seems architecture-dependent. FP16 may align policies in RL setups, while BF16 appears to stabilize recursive dynamics. To make FP16 work, normalization and range control techniques seem crucial, as also noted by @rasbt.Penghui Qi: 🚀Excited to share our new work! 💊Problem: The BF16 precision causes a large training-inference mismatch, leading to unstable RL training. 💡Solution: Just switch to FP16. 🎯That's it. 📰Paper: https://arxiv.org/pdf/2510.26788 ⭐️Code: https://github.com/sail-sg/Precision-RL Link: https://x.com/QPHutu/status/1984258808332550245
With the release of the Kimi Linear LLM last week, we can definitely see that efficient, linear attention variants have seen a resurgence in recent months. Here's a brief summary of what happened. First, linear attention variants have been around for a long time, and I remember seeing tons of papers in the 2020s. I don't want to dwell too long on these older attempts. But the bottom line was that they reduced both time and memory complexity from O(n^2) to O(n) to making attention much more efficient for long sequences. However, they never really gained traction as they degraded the model accuracy, and I have never really seen one of these variants applied in an open-weight state-of-the-art LLM. In the second half of this year, there was a bit of a revival of linear attention variants. The first notable model was MiniMax-M1 with lightning attention, a 456B parameter mixture-of-experts (MoE) model with 46B active parameters, which came out back in June. Then, in August, the Qwen3 team followed up with Qwen3-Next, which I discussed in more detail above. Then, in September, the DeepSeek Team announced DeepSeek V3.2 with sparse attention. All three models (MiniMax-M1, Qwen3-Next, DeepSeek V3.2) replace the traditional quadratic attention variants in most or all of their layers with efficient linear variants. (DeepSeek's sparse attention it's not strictly linear but still subquadratic). Interestingly, there was a recent plot twist, where the MiniMax team released their new 230B parameter M2 model (discussed in section 13) without linear attention, going back to regular attention. The team stated that linear attention is tricky in production LLMs. It seemed to work fine with regular prompts, but it had pure accuracy in reasoning and multi-turn tasks, which are not only important for regular chat sessions but also agentic applications. This could have been a turning point where linear attention may not be worth pursuing after all. However, it gets more interesting....

DGX Spark and Mac Mini for Local PyTorch Development
The DGX Spark for local LLM inferencing and fine-tuning was a pretty popular discussion topic recently. I got to play with one myself, primarily working with and on LLMs in PyTorch, and collected some benchmarks and takeaways.
Just saw the MiniMax-M2 benchmarks, and the performance is too good to ignore :). So, I just amended my "The Big LLM Architecture Comparison" with entry number 13! 1️⃣ Full attention modules: As shown in the overview figure below, I grouped MiniMax-M2 with the other decoder-style transformer LLMs as it does not use the efficient lightning attention variant proposed in MiniMax-M1. Instead, the developers went back to using full attention, likely to improve modeling (and benchmark) performance. 2️⃣ Per-layer QK-Norm: Overall, MiniMax-M2 is surprisingly similar to Qwen3. Besides changing the number of layers, sizes, etc., it uses the same components overall. Perhaps the one noteworthy highlight here is that MiniMax-M2 uses a so-called “per_layer” QK-Norm instead of the regular QK-Norm. A closer look at the code reveals the "per_layer" means that the RMSNorm (used for QK-Norm as explained earlier) is defined in each transformer block (as in regular QK-Norm), but, in addition, instead of reusing it across attention heads, it's a unique QK-Norm for each attention head. 3️⃣ Sliding-window attention: The model configuration file also includes a sliding-window attention setting (similar to Gemma 3), but, as in Mistral 3.1, it is disabled by default. Otherwise, besides the per-layer QK-Norm, the architecture is very similar to Qwen3, as shown in the figure below. 4️⃣ MoE sparsity: A perhaps interesting tidbit, as shown in the figure below, includes the fact that they don't use a shared expert (similar to Qwen3 but unlike Qwen3-Next). As mentioned earlier, in my opinion, shared experts are useful because they reduce redundancy among the other experts. Also, as apparent from the figure above, MiniMax-M2 is twice as "sparse" as Qwen3. I.e., at roughly the same size as Qwen3 235B-A22B, MiniMax-M2 has only 10B instead of 22B active experts per token (that is, 4.37% of the parameters are used in each inference step in MiniMax-M2, whereas Qwen3 uses 9.36% active tokens).

Understanding the 4 Main Approaches to LLM Evaluation (From Scratch)
Multiple-Choice Benchmarks, Verifiers, Leaderboards, and LLM Judges with Code Examples
Understanding and Implementing Qwen3 From Scratch
Previously, I compared the most notable open-weight architectures of 2025 in The Big LLM Architecture Comparison. Then, I zoomed in and discussed the various architecture components in From GPT-2 to gpt-oss: Analyzing the Architectural Advances on a conceptual level. Since all good things come in threes, before covering some of the noteworthy research highlights of this summer, I wanted to now dive into these architectures hands-on, in code. By following along, you will understand how it actually works under the hood and gain building blocks you can adapt for your own experiments or projects.
From GPT-2 to gpt-oss: Analyzing the Architectural Advances
OpenAI just released their new open-weight LLMs this week: gpt-oss-120b and gpt-oss-20b, their first open-weight models since GPT-2 in 2019. And yes, thanks to some clever optimizations, they can run locally. I spent the past few days reading through the code and technical reports to summarize the most interesting details.
The Big LLM Architecture Comparison
It has been seven years since the original GPT architecture was developed. At first glance, looking back at GPT-2 (2019) and forward to DeepSeek-V3 and Llama 4 (2024-2025), one might be surprised at how structurally similar these models still are. Comparing LLMs to determine the key ingredients that contribute to their good (or not-so-good) performance is notoriously challenging: datasets, training techniques, and hyperparameters vary widely and are often not well documented. However, I think that there is still a lot of value in examining the structural changes of the architectures themselves to see what LLM developers are up to in 2025.
LLM Research Papers: The 2025 List (January to June)
The latest in LLM research with a hand-curated, topic-organized list of over 200 research papers from 2025.
Understanding and Coding the KV Cache in LLMs from Scratch
KV caches are one of the most critical techniques for efficient inference in LLMs in production. KV caches are an important component for compute-efficient LLM inference in production. This article explains how they work conceptually and in code with a from-scratch, human-readable implementation.
Coding LLMs from the Ground Up: A Complete Course
Why build an LLM from scratch? It's probably the best and most efficient way to learn how LLMs really work. Plus, many readers have told me they had a lot of fun doing it.
The State of Reinforcement Learning for LLM Reasoning
A lot has happened this month, especially with the releases of new flagship models like GPT-4.5 and Llama 4. But you might have noticed that reactions to these releases were relatively muted. Why? One reason could be that GPT-4.5 and Llama 4 remain conventional models, which means they were trained without explicit reinforcement learning for reasoning. However, OpenAI's recent release of the o3 reasoning model demonstrates there is still considerable room for improvement when investing compute strategically, specifically via reinforcement learning methods tailored for reasoning tasks. While reasoning alone isn't a silver bullet, it reliably improves model accuracy and problem-solving capabilities on challenging tasks (so far). And I expect reasoning-focused post-training to become standard practice in future LLM pipelines. So, in this article, let's explore the latest developments in reasoning via reinforcement learning.
First Look at Reasoning From Scratch: Chapter 1
As you know, I've been writing a lot lately about the latest research on reasoning in LLMs. Before my next research-focused blog post, I wanted to offer something special to my paid subscribers as a thank-you for your ongoing support. So, I've started writing a new book on how reasoning works in LLMs, and here I'm sharing the first Chapter 1 with you. This ~15-page chapter is an introduction reasoning in the context of LLMs and provides an overview of methods like inference-time scaling and reinforcement learning. Thanks for your support! I hope you enjoy the chapter, and stay tuned for my next blog post on reasoning research!
Inference-Time Compute Scaling Methods to Improve Reasoning Models
This article explores recent research advancements in reasoning-optimized LLMs, with a particular focus on inference-time compute scaling that have emerged since the release of DeepSeek R1.
Understanding Reasoning LLMs
In this article, I will describe the four main approaches to building reasoning models, or how we can enhance LLMs with reasoning capabilities. I hope this provides valuable insights and helps you navigate the rapidly evolving literature and hype surrounding this topic.
Noteworthy LLM Research Papers of 2024
This article covers 12 influential AI research papers of 2024, ranging from mixture-of-experts models to new LLM scaling laws for precision.
Implementing A Byte Pair Encoding (BPE) Tokenizer From Scratch
This is a standalone notebook implementing the popular byte pair encoding (BPE) tokenization algorithm, which is used in models like GPT-2 to GPT-4, Llama 3, etc., from scratch for educational purposes."
LLM Research Papers: The 2024 List
I want to share my running bookmark list of many fascinating (mostly LLM-related) papers I stumbled upon in 2024. It's just a list, but maybe it will come in handy for those who are interested in finding some gems to read for the holidays.
Understanding Multimodal LLMs
There has been a lot of new research on the multimodal LLM front, including the latest Llama 3.2 vision models, which employ diverse architectural strategies to integrate various data types like text and images. For instance, The decoder-only method uses a single stack of decoder blocks to process all modalities sequentially. On the other hand, cross-attention methods (for example, used in Llama 3.2) involve separate encoders for different modalities with a cross-attention layer that allows these encoders to interact. This article explains how these different types of multimodal LLMs function. Additionally, I will review and summarize roughly a dozen other recent multimodal papers and models published in recent weeks to compare their approaches.
Building A GPT-Style LLM Classifier From Scratch
This article shows you how to transform pretrained large language models (LLMs) into strong text classifiers. But why focus on classification? First, finetuning a pretrained model for classification offers a gentle yet effective introduction to model finetuning. Second, many real-world and business challenges revolve around text classification: spam detection, sentiment analysis, customer feedback categorization, topic labeling, and more.
Building LLMs from the Ground Up: A 3-hour Coding Workshop
This tutorial is aimed at coders interested in understanding the building blocks of large language models (LLMs), how LLMs work, and how to code them from the ground up in PyTorch. We will kick off this tutorial with an introduction to LLMs, recent milestones, and their use cases. Then, we will code a small GPT-like LLM, including its data input pipeline, core architecture components, and pretraining code ourselves. After understanding how everything fits together and how to pretrain an LLM, we will learn how to load pretrained weights and finetune LLMs using open-source libraries.
New LLM Pre-training and Post-training Paradigms
There are hundreds of LLM papers each month proposing new techniques and approaches. However, one of the best ways to see what actually works well in practice is to look at the pre-training and post-training pipelines of the most recent state-of-the-art models. Luckily, four major new LLMs have been released in the last months, accompanied by relatively detailed technical reports. In this article, I focus on the pre-training and post-training pipelines of the following models: Alibaba's Qwen 2, Apple Intelligence Foundation Language Models, Google's Gemma 2, Meta AI's Llama 3.1.
Instruction Pretraining LLMs
This article covers a new, cost-effective method for generating data for instruction finetuning LLMs; instruction finetuning from scratch; pretraining LLMs with instruction data; and an overview of what's new in Gemma 2.
Developing an LLM: Building, Training, Finetuning
This is an overview of the LLM development process. This one-hour talk focuses on the essential three stages of developing an LLM: coding the architecture, implementing pretraining, and fine-tuning the LLM. Lastly, we also discuss the main ways LLMs are evaluated, along with the caveats of each method.
LLM Research Insights: Instruction Masking and New LoRA Finetuning Experiments?
This article covers three new papers related to instruction finetuning and parameter-efficient finetuning with LoRA in large language models (LLMs). I work with these methods on a daily basis, so it's always exciting to see new research that provides practical insights.
How Good Are the Latest Open LLMs? And Is DPO Better Than PPO?
What a month! We had four major open LLM releases: Mixtral, Meta AI's Llama 3, Microsoft's Phi-3, and Apple's OpenELM. In my new article, I review and discuss all four of these major transformer-based LLM model releases, followed by new research on reinforcement learning with human feedback methods for instruction finetuning using PPO and DPO algorithms.
Using and Finetuning Pretrained Transformers
What are the different ways to use and finetune pretrained large language models (LLMs)? The three most common ways to use and finetune pretrained LLMs include a feature-based approach, in-context prompting, and updating a subset of the model parameters. First, most pretrained LLMs or language transformers can be utilized without the need for further finetuning. For instance, we can employ a feature-based method to train a new downstream model, such as a linear classifier, using embeddings generated by a pretrained transformer. Second, we can showcase examples of a new task within the input itself, which means we can directly exhibit the expected outcomes without requiring any updates or learning from the model. This concept is also known as prompting. Finally, it’s also possible to finetune all or just a small number of parameters to achieve the desired outcomes. This article discusses these types of approaches in greater depth
Tips for LLM Pretraining and Evaluating Reward Models
It's another month in AI research, and it's hard to pick favorites. This month, I am going over a paper that discusses strategies for the continued pretraining of LLMs, followed by a discussion of reward modeling used in reinforcement learning with human feedback (a popular LLM alignment method), along with a new benchmark. Continued pretraining for LLMs is an important topic because it allows us to update existing LLMs, for instance, ensuring that these models remain up-to-date with the latest information and trends. Also, it allows us to adapt them to new target domains without having them to retrain from scratch. Reward modeling is important because it allows us to align LLMs more closely with human preferences and, to some extent, helps with safety. But beyond human preference optimization, it also provides a mechanism for learning and adapting LLMs to complex tasks by providing instruction-output examples where explicit programming of correct behavior is challenging or impracti...
Research Papers in February 2024
Once again, this has been an exciting month in AI research. This month, I'm covering two new openly available LLMs, insights into small finetuned LLMs, and a new parameter-efficient LLM finetuning technique. The two LLMs mentioned above stand out for several reasons. One LLM (OLMo) is completely open source, meaning that everything from the training code to the dataset to the log files is openly shared. The other LLM (Gemma) also comes with openly available weights but achieves state-of-the-art performance on several benchmarks and outperforms popular LLMs of similar size, such as Llama 2 7B and Mistral 7B, by a large margin.
Improving LoRA: Implementing Weight-Decomposed Low-Rank Adaptation (DoRA) from Scratch
Low-rank adaptation (LoRA) is a machine learning technique that modifies a pretrained model (for example, an LLM or vision transformer) to better suit a specific, often smaller, dataset by adjusting only a small, low-rank subset of the model's parameters. In this article, we will take a look at both LoRA and DoRA, which is a new promising alternative to LoRA.
Optimizing LLMs From a Dataset Perspective
This article focuses on improving the modeling performance of LLMs by finetuning them using carefully curated datasets. Specifically, this article highlights strategies that involve modifying, utilizing, or manipulating the datasets for instruction-based finetuning rather than altering the model architecture or training algorithms (the latter will be topics of a future article). This article will also explain how you can prepare your own datasets to finetune open-source LLMs.
The NeurIPS 2023 LLM Efficiency Challenge Starter Guide
Large language models (LLMs) offer one of the most interesting opportunities for developing more efficient training methods. A few weeks ago, the NeurIPS 2023 LLM Efficiency Challenge launched to focus on efficient LLM finetuning, and this guide is a short walkthrough explaining how to participate in this competition. This article covers everything you need to know, from setting up the coding environment to making the first submission.
Optimizing Memory Usage for Training LLMs and Vision Transformers in PyTorch
Peak memory consumption is a common bottleneck when training deep learning models such as vision transformers and LLMs. This article provides a series of techniques that can lower memory consumption by approximately 20x without sacrificing modeling performance and prediction accuracy.
Finetuning Falcon LLMs More Efficiently With LoRA and Adapters
Finetuning allows us to adapt pretrained LLMs in a cost-efficient manner. But which method should we use? This article compares different parameter-efficient finetuning methods for the latest top-performing open-source LLM, Falcon. Using parameter-efficient finetuning methods outlined in this article, it's possible to finetune an LLM in 1 hour on a single GPU instead of a day on 6 GPUs.
Accelerating Large Language Models with Mixed-Precision Techniques
Training and using large language models (LLMs) is expensive due to their large compute requirements and memory footprints. This article will explore how leveraging lower-precision formats can enhance training and inference speeds up to 3x without compromising model accuracy.
Parameter-Efficient LLM Finetuning With Low-Rank Adaptation (LoRA)
Pretrained large language models are often referred to as foundation models for a good reason: they perform well on various tasks, and we can use them as a foundation for finetuning on a target task. As an alternative to updating all layers, which is very expensive, parameter-efficient methods such as prefix tuning and adapters have been developed. Let's talk about one of the most popular parameter-efficient finetuning techniques: Low-rank adaptation (LoRA). What is LoRA? How does it work? And how does it compare to the other popular finetuning approaches? Let's answer all these questions in this article!
Understanding Parameter-Efficient Finetuning of Large Language Models: From Prefix Tuning to LLaMA-Adapters
In the rapidly evolving field of artificial intelligence, utilizing large language models in an efficient and effective manner has become increasingly important. Parameter-efficient finetuning stands at the forefront of this pursuit, allowing researchers and practitioners to reuse pretrained models while minimizing their computational and resource footprints. This article explains the broad concept of finetuning and discusses popular parameter-efficient alternatives like prefix tuning and adapters. Finally, we will look at the recent LLaMA-Adapter method and see how we can use it in practice.
Finetuning Large Language Models On A Single GPU Using Gradient Accumulation
Previously, I shared an article using multi-GPU training strategies to speed up the finetuning of large language models. Several of these strategies include mechanisms such as model or tensor sharding that distributes the model weights and computations across different devices to work around GPU memory limitations. However, many of us don't have access to multi-GPU resources. So, this article illustrates a simple technique that works as a great workaround to train models with larger batch sizes when GPU memory is a concern: gradient accumulation.
Keeping Up With AI Research And News
When it comes to productivity workflows, there are a lot of things I'd love to share. However, the one topic many people ask me about is how I keep up with machine learning and AI at large, and how I find interesting papers.
Some Techniques To Make Your PyTorch Models Train (Much) Faster
This blog post outlines techniques for improving the training performance of your PyTorch model without compromising its accuracy. To do so, we will wrap a PyTorch model in a LightningModule and use the Trainer class to enable various training optimizations. By changing only a few lines of code, we can reduce the training time on a single GPU from 22.53 minutes to 2.75 minutes while maintaining the model's prediction accuracy. Yes, that's a 8x performance boost!
Understanding and Coding the Self-Attention Mechanism of Large Language Models From Scratch
In this article, we are going to understand how self-attention works from scratch. This means we will code it ourselves one step at a time. Since its introduction via the original transformer paper, self-attention has become a cornerstone of many state-of-the-art deep learning models, particularly in the field of Natural Language Processing. Since self-attention is now everywhere, it's important to understand how it works.
Understanding Large Language Models -- A Transformative Reading List
Since transformers have such a big impact on everyone's research agenda, I wanted to flesh out a short reading list for machine learning researchers and practitioners getting started with large language models.
What Are the Different Approaches for Detecting Content Generated by LLMs Such As ChatGPT? And How Do They Work and Differ?
Since the release of the AI Classifier by OpenAI made big waves yesterday, I wanted to share a few details about the different approaches for detecting AI-generated text. This article briefly outlines four approaches to identifying AI-generated contents.
Comparing Different Automatic Image Augmentation Methods in PyTorch
Data augmentation is a key tool in reducing overfitting, whether it's for images or text. This article compares three Auto Image Data Augmentation techniques in PyTorch: AutoAugment, RandAugment, and TrivialAugment.
Curated Resources and Trustworthy Experts: The Key Ingredients for Finding Accurate Answers to Technical Questions in the Future
Conversational chat bots such as ChatGPT probably will not be able replace traditional search engines and expert knowledge anytime soon. With the vast amount of misinformation available on the internet, the ability to distinguish between credible and unreliable sources remains challenging and crucial.
Training an XGBoost Classifier Using Cloud GPUs Without Worrying About Infrastructure
Imagine you want to quickly train a few machine learning or deep learning models on the cloud but don't want to deal with cloud infrastructure. This short article explains how we can get our code up and running in seconds using the open source lightning library.
Open Source Highlights 2022 for Machine Learning & AI
Recently, I shared the top 10 papers that I read in 2022. As a follow-up, I am compiling a list of my favorite 10 open-source releases that I discovered, used, or contributed to in 2022.
Influential Machine Learning Papers Of 2022
Every day brings something new and exciting to the world of machine learning and AI, from the latest developments and breakthroughs in the field to emerging trends and challenges. To mark the start of the new year, below is a short review of the top ten papers I've read in 2022.
Ahead Of AI, And What's Next?
About monthly machine learning musings, and other things I am currently workin on ...
A Short Chronology Of Deep Learning For Tabular Data
Occasionally, I share research papers proposing new deep learning approaches for tabular data on social media, which is typically an excellent discussion starter. Often, people ask for additional methods or counterexamples. So, with this short post, I aim to briefly summarize the major papers on deep tabular learning I am currently aware of. However, I want to emphasize that no matter how interesting or promising deep tabular methods look, I still recommend using a conventional machine learning method as a baseline. There is a reason why I cover conventional machine learning before deep learning in my books.
No, We Don't Have to Choose Batch Sizes As Powers Of 2
Regarding neural network training, I think we are all guilty of doing this: we choose our batch sizes as powers of 2, that is, 64, 128, 256, 512, 1024, and so forth. There are some valid theoretical justifications for this, but how does it pan out in practice? We had some discussions about that in the last couple of days, and here I want to write down some of the take-aways so I can reference them in the future. I hope you'll find this helpful as well!
Sharing Deep Learning Research Models with Lightning Part 2: Leveraging the Cloud
In this article, we will take deploy a Super Resolution App on the cloud using lightning.ai. The primary goal here is to see how easy it is to create and share a research demo. However, the cloud is for more than just model sharing: we will also learn how we can tap into additional GPU resources for model training.
Sharing Deep Learning Research Models with Lightning Part 1: Building A Super Resolution App
In this post, we will build a Lightning App. Why? Because it is 2022, and it is time to explore a more modern take on interacting with, presenting, and sharing our deep learning models. We are going to tackle this in three parts. In this first part, we will learn what a Lightning App is and how we build a Super Resolution GAN demo.
Taking Datasets, DataLoaders, and PyTorch’s New DataPipes for a Spin
The PyTorch team recently announced TorchData, a prototype library focused on implementing composable and reusable data loading utilities for PyTorch. In particular, the TorchData library is centered around DataPipes, which are meant to be a DataLoader-compatible replacement for the existing Dataset class.
Running PyTorch on the M1 GPU
Today, PyTorch officially introduced GPU support for Apple's ARM M1 chips. This is an exciting day for Mac users out there, so I spent a few minutes trying it out in practice. In this short blog post, I will summarize my experience and thoughts with the M1 chip for deep learning tasks.
Creating Confidence Intervals for Machine Learning Classifiers
Developing good predictive models hinges upon accurate performance evaluation and comparisons. However, when evaluating machine learning models, we typically have to work around many constraints, including limited data, independence violations, and sampling biases. Confidence intervals are no silver bullet, but at the very least, they can offer an additional glimpse into the uncertainty of the reported accuracy and performance of a model. This article outlines different methods for creating confidence intervals for machine learning models. Note that these methods also apply to deep learning.
Losses Learned
The cross-entropy loss is our go-to loss for training deep learning-based classifiers. In this article, I am giving you a quick tour of how we usually compute the cross-entropy loss and how we compute it in PyTorch. There are two parts to it, and here we will look at a binary classification context first. You may wonder why bother writing this article; computing the cross-entropy loss should be relatively straightforward!? Yes and no. We can compute the cross-entropy loss in one line of code, but there's a common gotcha due to numerical optimizations under the hood. (And yes, when I am not careful, I sometimes make this mistake, too.) So, in this article, let me tell you a bit about deep learning jargon, improving numerical performance, and what could go wrong.