Simon Willison
简介
Creator @datasetteproj, co-creator Django. PSF board. Hangs out with @natbat. He/Him. Mastodon: https://t.co/t0MrmnJW0K Bsky: https://t.co/OnWIyhX4CH
平台
内容历史
Activity on simonw/datasette
simonw commented on an issue in datasette
simonw commented on an issue in datasette
View on GitHubActivity on simonw/datasette
simonw commented on an issue in datasette
simonw commented on an issue in datasette
View on GitHubActivity on simonw/datasette
simonw commented on an issue in datasette
simonw commented on an issue in datasette
View on GitHubActivity on simonw/datasette
simonw commented on an issue in datasette
simonw commented on an issue in datasette
View on GitHubActivity on simonw/datasette
simonw commented on an issue in datasette
simonw commented on an issue in datasette
View on GitHubActivity on simonw/datasette
simonw commented on an issue in datasette
simonw commented on an issue in datasette
View on GitHubI still sometimes see people saying "if you know how to write the code, it's faster to write it yourself" I'd argue the exact opposite: if you know how to write it, you gain nothing from doing the typing yourself - outsource that to a coding agent!
Activity on simonw/datasette
simonw commented on an issue in datasette
simonw commented on an issue in datasette
View on GitHubActivity on simonw/datasette
simonw commented on an issue in datasette
simonw commented on an issue in datasette
View on GitHubActivity on simonw/datasette
simonw commented on an issue in datasette
simonw commented on an issue in datasette
View on GitHubReleased simonw/datasette-block-robots
simonw released 1.1.1 at simonw/datasette-block-robots
simonw released 1.1.1 at simonw/datasette-block-robots
Activity on repository
simonw pushed datasette-block-robots
simonw pushed datasette-block-robots
View on GitHubActivity on repository
simonw pushed datasette-block-robots
simonw pushed datasette-block-robots
View on GitHubActivity on repository
simonw pushed datasette-block-robots
simonw pushed datasette-block-robots
View on GitHubActivity on simonw/datasette
simonw commented on an issue in datasette
simonw commented on an issue in datasette
View on GitHubActivity on simonw/datasette
simonw labeled an issue in datasette
simonw labeled an issue in datasette
View on GitHubReleased simonw/datasette-allow-permissions-debug
simonw released 0.2a1 at simonw/datasette-allow-permissions-debug
simonw released 0.2a1 at simonw/datasette-allow-permissions-debug
Activity on repository
simonw pushed datasette-allow-permissions-debug
simonw pushed datasette-allow-permissions-debug
View on GitHubActivity on repository
simonw pushed datasette-allow-permissions-debug
simonw pushed datasette-allow-permissions-debug
View on GitHubQuoting GitHub Changeling
Dependabot now waits until a new release has been available on its registry for at least three days before opening a version update pull request. This cooldown is now the default and requires no configuration. — GitHub Changeling, embracing dependency cooldowns Tags: dependency-cooldowns, packaging, security, github
simonw/pedalican

simonw/pedalican Clearly I wasn't paying attention when these were first announced back in May, but today I accidentally activated a "pet" in Codex Desktop - a little animated robot, reminiscent of Clippy - and then learned you can create your own. So I did, and now I have a cute little pelican on a bicycle bouncing around my desktop giving me updates on my Codex tasks. Your browser does not support HTML5 video. The most interesting thing about this process was watching how the custom pet was created. I told it I wanted a custom pet that was a pelican riding a bicycle and GPT-5.6 Sol xhigh did the rest of the work, using several rounds with gpt-image-2 to generate the necessary sprite assets. I had it make extensive notes and record all of the intermediary steps. My GItHub repo includes every generated image and combined sprite sheet, plus GIFs for each of the animation loops such as this one, called waving.gif: That GIF was compiled from a single image generate...
lobste.rs is now running on SQLite
lobste.rs is now running on SQLite Community site Lobsters has been planning a migration away from MariaDB since August 2018 - originally targeting PostgreSQL, but last year they decided to investigate SQLite instead. This weekend they completed the migration, and now consider it stable enough that it looks like this is the permanent architecture for the site going forward: SQLite seems to have passed with flying colors: cpu usage is down, memory usage is down, site seems to be snappier at least for me, 1/2 the vps cost once mariadb vps is taken down The Lobsters Rails application now runs on a single VPS, with a primary content SQLite database file that's around 3.8GB. There are plenty more details in both the linked thread and this SQLite migration PR by Thomas Dziedzic, which added 735 lines and removed 593 lines across 30 commits and 188 files. That PR built on top of previous PRs #1705, #1871, and #1924. This is a really useful case study, and a great reminder that you ...
Quoting Armin Ronacher
The shared language of a software project is not English or Python but it is the common understanding of what its concepts mean, where the boundaries are, which invariants matter, who owns what, and why the system has the shape it does. This language is rarely written down in one place. It lives partly in documentation and code, but also in code review, conversations, arguments, and the experience of having to explain a change to somebody else. Before agents, some of this shared understanding was maintained by friction. If I wanted to change your storage layer, I usually had to read your code, ask you questions, and perhaps coordinate with another team whose service depended on it. This was slow, and much of that slowness was waste but not all of it was. Some of it was the process by which your understanding became mine, and by which both of us discovered whether we still agreed about how the system worked. This friction synchronizes people. — Armin Ronacher, The Tower Ke...
Released simonw/datasette
simonw released 1.0a37 at simonw/datasette
simonw released 1.0a37 at simonw/datasette
Activity on simonw/datasette
simonw commented on an issue in datasette
simonw commented on an issue in datasette
View on GitHubActivity on simonw/datasette
simonw commented on an issue in datasette
simonw commented on an issue in datasette
View on GitHubActivity on simonw/datasette
simonw commented on an issue in datasette
simonw commented on an issue in datasette
View on GitHubActivity on simonw/datasette
simonw opened a pull request in datasette
simonw opened a pull request in datasette
View on GitHubSo I guess Codex has a little robot now? (It's not as cute as the Claw'd crab)
Activity on repository
simonw pushed speech-analyzer-cli
simonw pushed speech-analyzer-cli
View on GitHubActivity on repository
simonw pushed speech-analyzer-cli
simonw pushed speech-analyzer-cli
View on GitHubActivity on repository
simonw pushed speech-analyzer-cli
simonw pushed speech-analyzer-cli
View on GitHubActivity on repository
simonw pushed speech-analyzer-cli
simonw pushed speech-analyzer-cli
View on GitHubActivity on simonw/datasette
simonw commented on an issue in datasette
simonw commented on an issue in datasette
View on GitHubActivity on simonw/datasette
simonw opened a pull request in datasette
simonw opened a pull request in datasette
View on GitHubActivity on simonw/datasette
simonw opened a pull request in datasette
simonw opened a pull request in datasette
View on GitHubActivity on simonw/datasette
simonw contributed to simonw/datasette
simonw contributed to simonw/datasette
View on GitHubActivity on simonw/datasette
simonw labeled an issue in datasette
simonw labeled an issue in datasette
View on GitHubNew TIL: Using uvx in GitHub Actions in a cache-friendly way I finally found a recipe that I like for running `uvx tool-name` in GitHub Actions without downloading a fresh copy of the package every time https://til.simonwillison.net/github-actions/uvx-github-actions-cache
Using uvx in GitHub Actions in a cache-friendly way
TIL: Using uvx in GitHub Actions in a cache-friendly way I finally found a cache-friendly recipe for using uvx tool-name in GitHub Actions workflows that I like. The trick is setting a UV_EXCLUDE_NEWER: "2026-07-12" environment variable at the start of the workflow and then using that as part of the GitHub Actions cache key. This means any uvx tool-name commands will resolve to the most recent version as-of that date, and you can bust the cache and upgrade the tools by bumping the date in the future. My goal here is to use Python tools in GitHub Actions without every run of the workflow hitting PyPI to download a fresh copy of the tool and its dependencies. Tags: packaging, pypi, python, github-actions, uv
DOOMQL
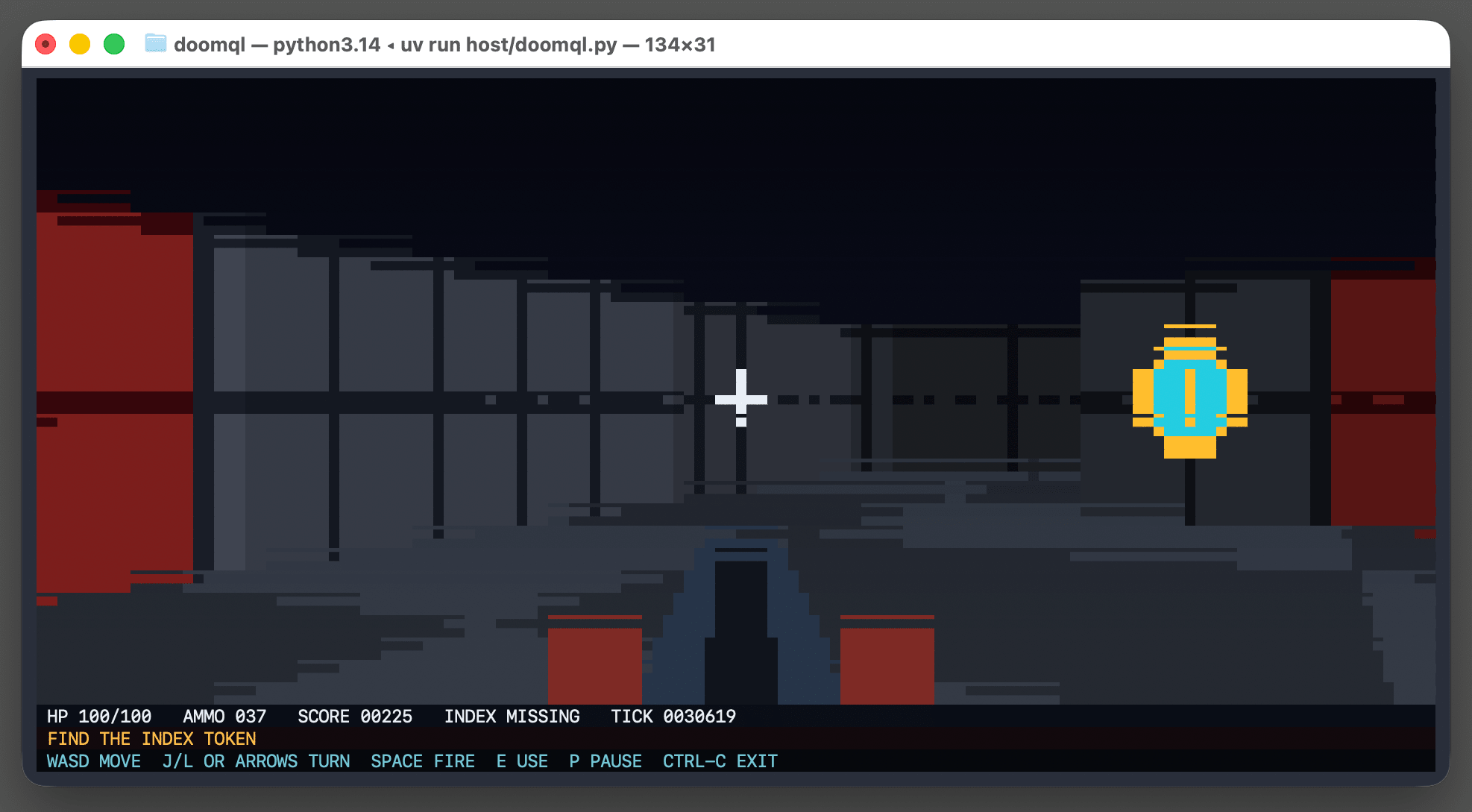
DOOMQL Peter Gostev built this using GPT-5.6 Sol. This is a lot of fun: DOOMQL started with a deliberately unreasonable question: what if SQLite were the game engine, not merely the place where a game stores data? The result is a small, original Doom-like game in which SQL owns movement, collision, enemies, combat, progression and every RGB pixel on screen. It's implemented as a Python terminal script - I tried it out like this: cd /tmp git clone https://github.com/petergpt/doomql cd doomql uv run host/doomql.py Here's the huge SQL query that implements a full ray tracer in SQLite using a recursive CTE. Running the above script creates a /tmp/doomql/.doomql/doomql.sqlite SQLite database, which you can explore using Datasette like this: uvx --prerelease=allow --with datasette-apps datasette \ /tmp/doomql/.doomql/doomql.sqlite \ -p 4444 --root --secret 1 --internal internal.db The --with datasette-apps option installs the new Datasette Apps plugin, which supports crea...
It's been about six months since OpenClaw burst onto the scene - are you still using yours? Did it become a daily driver? Any interesting lessons or anecdotes you can share?
datasette code-frequency chart on GitHub
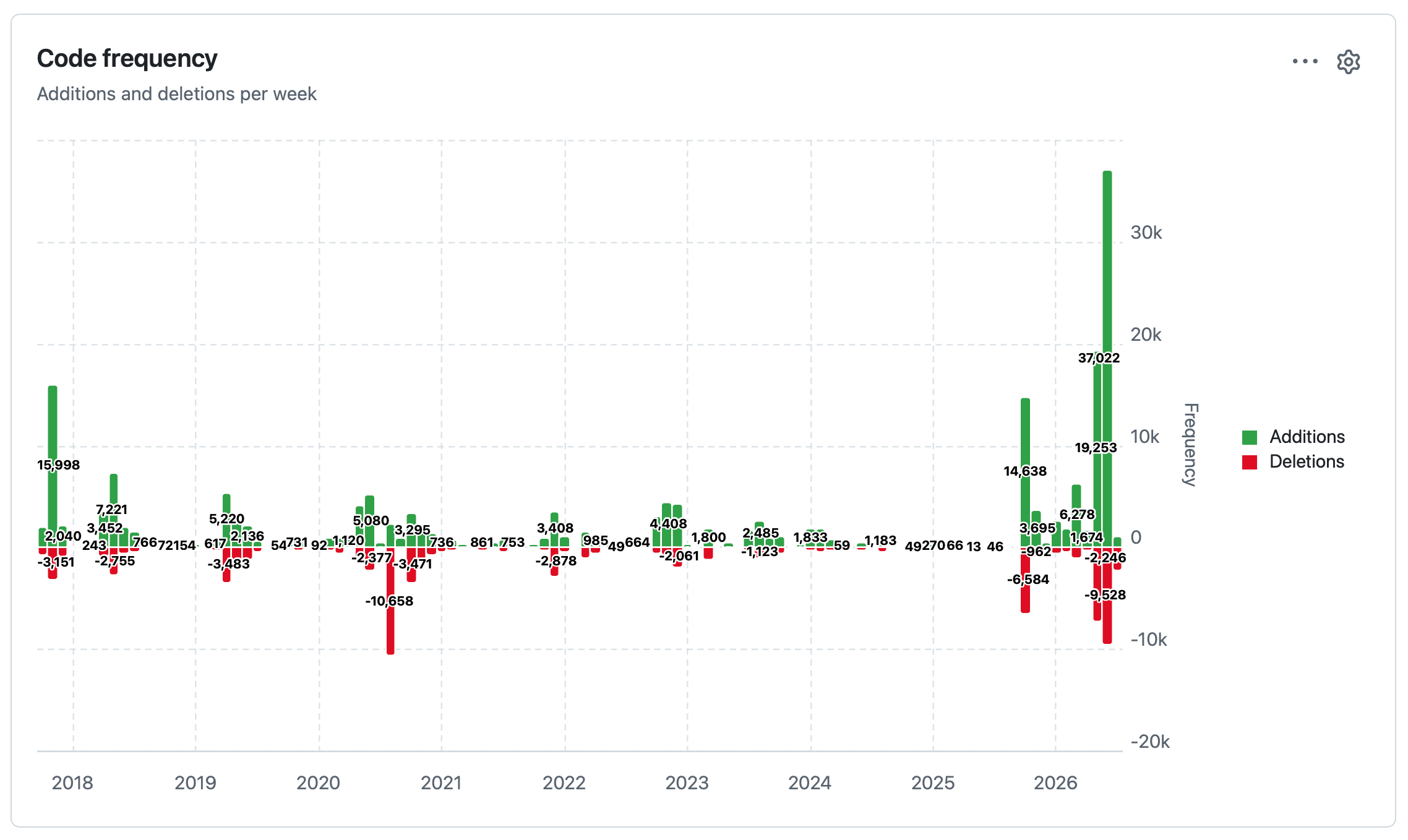
datasette code-frequency chart on GitHub Out of curiosity I decided to see if I could find a useful illustration of the impact of coding agents and Opus 4.5 class models on my own output. The best I've found so far is this GitHub chart of frequency of code changes to my Datasette open source project: The big spike in activity at the end aligns with Opus 4.8, GPT-5.5, Fable 5 and GPT-5.6 Sol. Tags: github, ai, datasette, generative-ai, llms, ai-assisted-programming, coding-agents
Activity on simonw/datasette
simonw closed an issue in datasette
simonw closed an issue in datasette
View on GitHubActivity on simonw/datasette
simonw commented on an issue in datasette
simonw commented on an issue in datasette
View on GitHubActivity on simonw/datasette
simonw opened an issue in datasette
simonw opened an issue in datasette
View on GitHubDirectly Responsible Individuals (DRI)
Directly Responsible Individuals (DRI) I went looking for a definition of "Directly Responsible Individuals" and the best I found was in the GitLab handbook. Apparently the term originated at Apple, where it's used to describe the person who is "ultimately accountable for the success or failure of a specific project, initiative, or activity". I've been thinking about this term recently in the context of LLM-powered agents and how they fit into human organizations. I don't think an agent should ever be considered the DRI for a project - that's something that feels uniquely human to me, because humans can take accountability for their actions where machines cannot. (See also IBM's legendary 1979 training slide that states "A computer can never be held accountable, therefore a computer must never make a management decision.") Tags: apple, management, ai, gitlab, generative-ai, llms, ai-ethics, coding-agents
shot-scraper 1.11
Release: shot-scraper 1.11 Some minor improvements, mainly around command option consistency and making the server: mechanism used by both shot-scraper video and shot-scraper multi work if the server takes longer than a second to start serving traffic. server: processes used by shot-scraper multi and shot-scraper video now wait up to 30 seconds for the target URL to accept connections, polling for port availability and replacing the previous fixed one-second delay. #197 The shot-scraper, pdf, html, accessibility and har commands now have a --js-file option for loading JavaScript from a local file, standard input or gh:username/script, as an alternative to --javascriptwhich accepts the string of JavaScript directly as an argument. #192 shot-scraper multi supports the equivalent js_file: YAML key. The shot-scraper javascript and shot-scraper html commands now have a --timeout option for consistency with other commands. #118 Tags: shot-scrap...
Released simonw/shot-scraper
simonw released 1.11 at simonw/shot-scraper
simonw released 1.11 at simonw/shot-scraper
Activity on simonw/shot-scraper
simonw closed an issue in shot-scraper
simonw closed an issue in shot-scraper
View on GitHubActivity on simonw/shot-scraper
simonw closed an issue in shot-scraper
simonw closed an issue in shot-scraper
View on GitHubActivity on simonw/shot-scraper
simonw closed an issue in shot-scraper
simonw closed an issue in shot-scraper
View on GitHubActivity on simonw/shot-scraper
simonw closed an issue in shot-scraper
simonw closed an issue in shot-scraper
View on GitHubActivity on simonw/shot-scraper
simonw commented on pull request simonw/shot-scraper#204
simonw commented on pull request simonw/shot-scraper#204
View on GitHubActivity on simonw/shot-scraper
simonw commented on pull request simonw/shot-scraper#204
simonw commented on pull request simonw/shot-scraper#204
View on GitHub